
|
|
|
|
|
|
|
|
|
|
|
Download (annotations) |
Videos at CVPR'2020 |
 Analysis |
GitHub Repo |
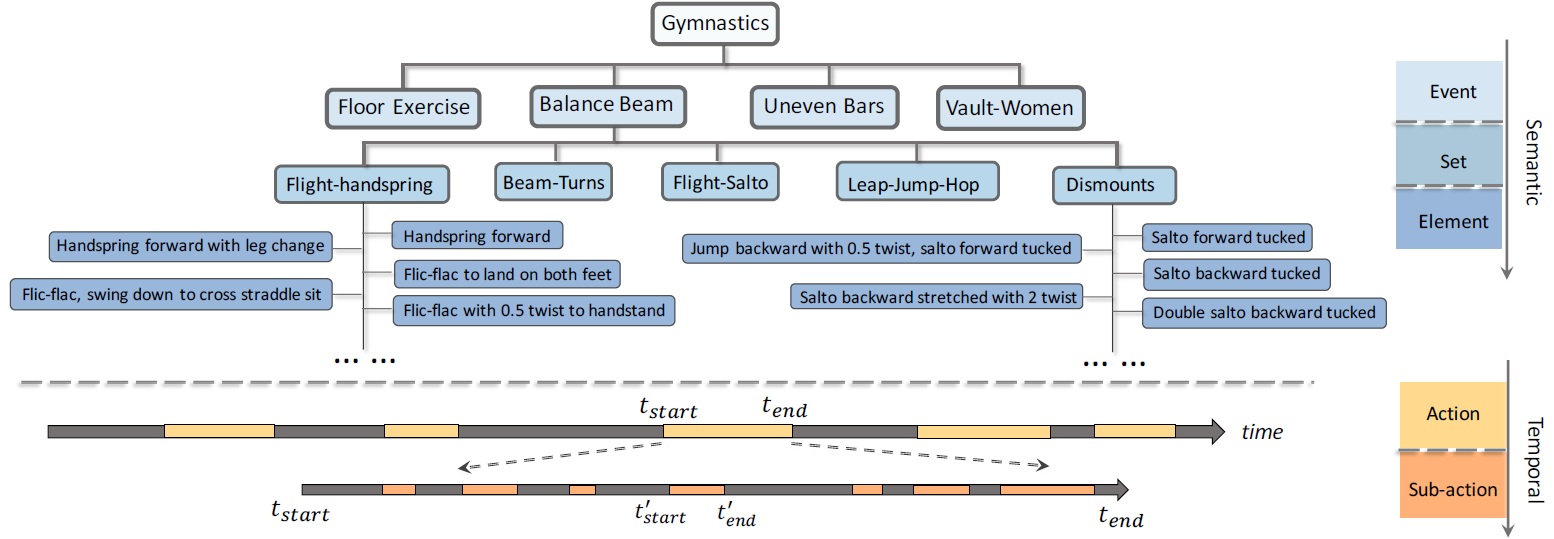
| An illustrative video of FineGym's hiecharcial annotations given a complete competition. Action and subaction boundaries are highlighted while irrelevant fragments are fast-forwarded. We also present the tree-based process at the end of the demo video. |
 |
|
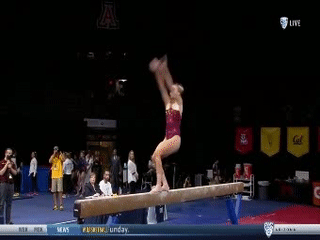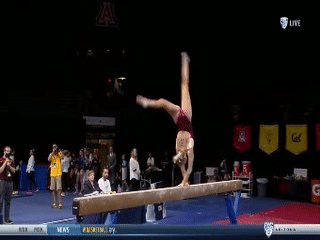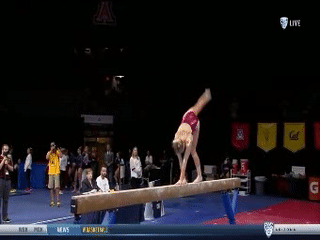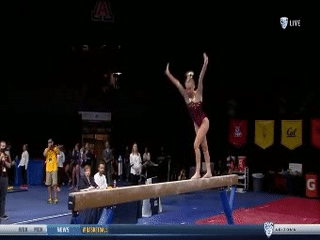

|



|
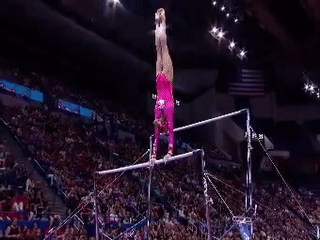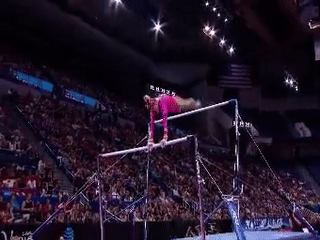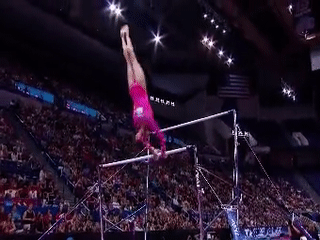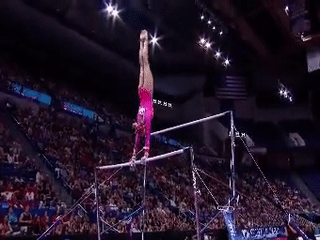
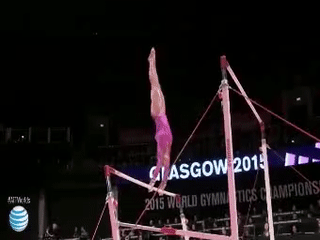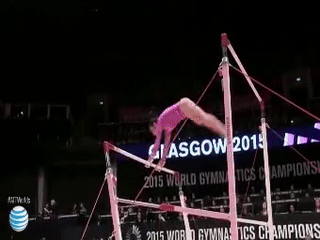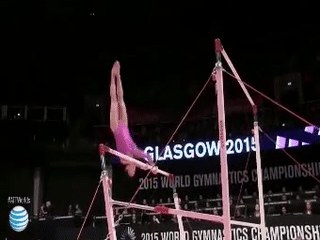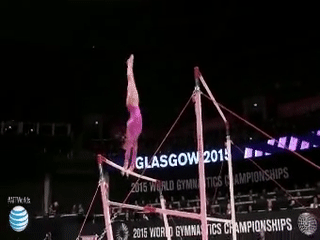

|



|
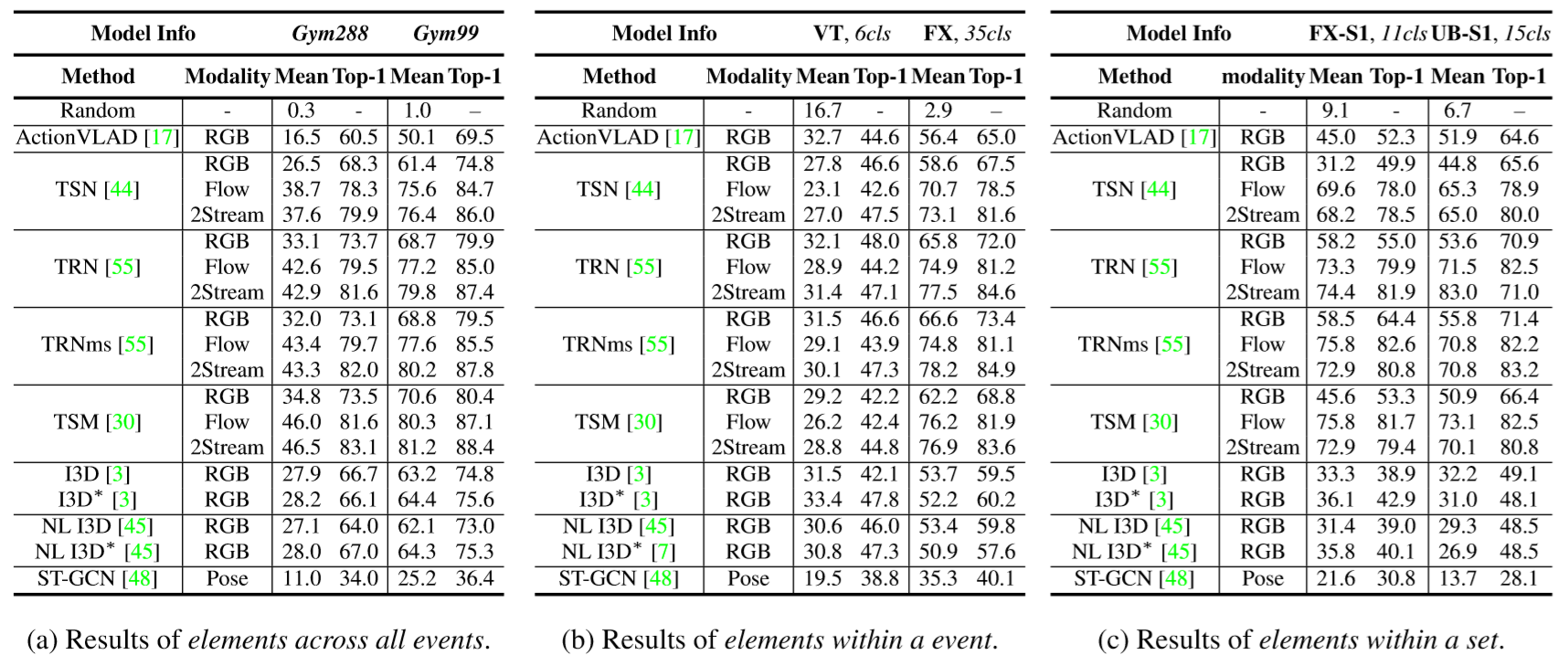 |
| Element-level action recognition results of representative methods. |
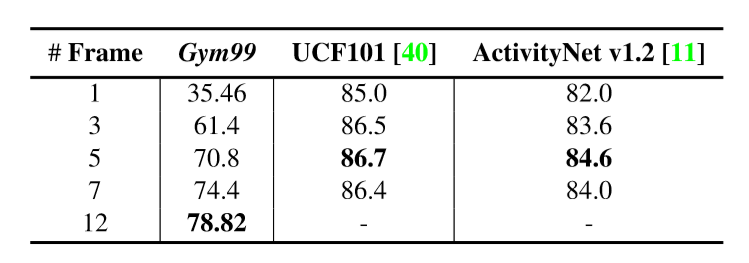 |
| Performances of TSN when varying the number of sampled frames during training. |
 |
|
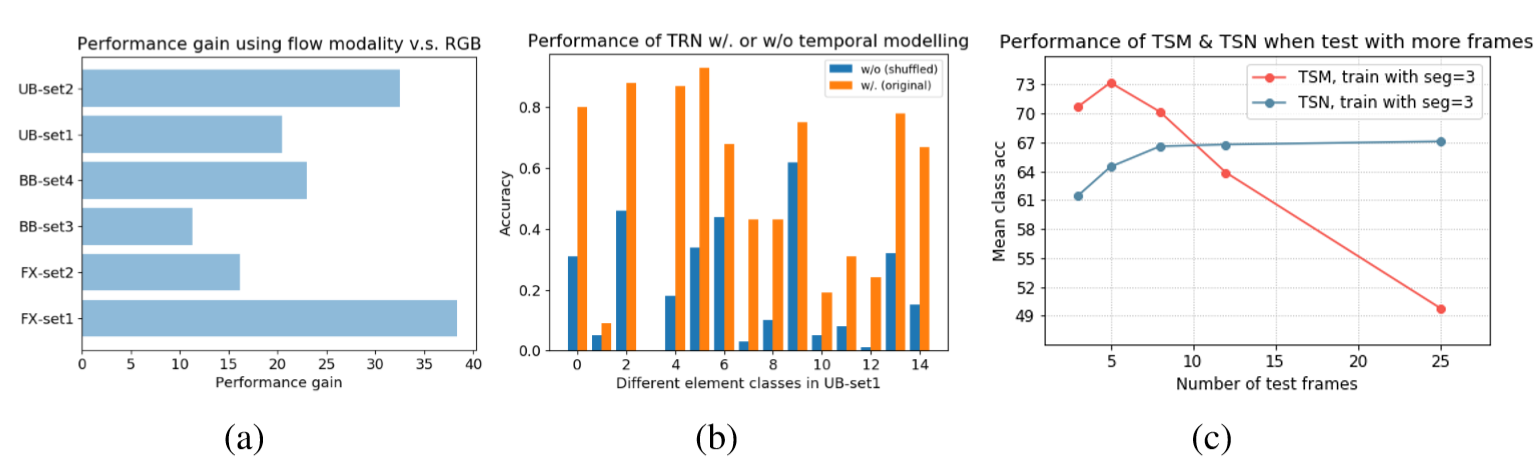
(a) Per-class performances of TSN with motion and appearance features in 6 element categories. (b) Performances of TRN on the set UB-circles using ordered or shuffled testing frames. (c) Mean-class accuracies of TSM and TSN on Gym99 when trained with 3 frames and tested with more frames. |
|
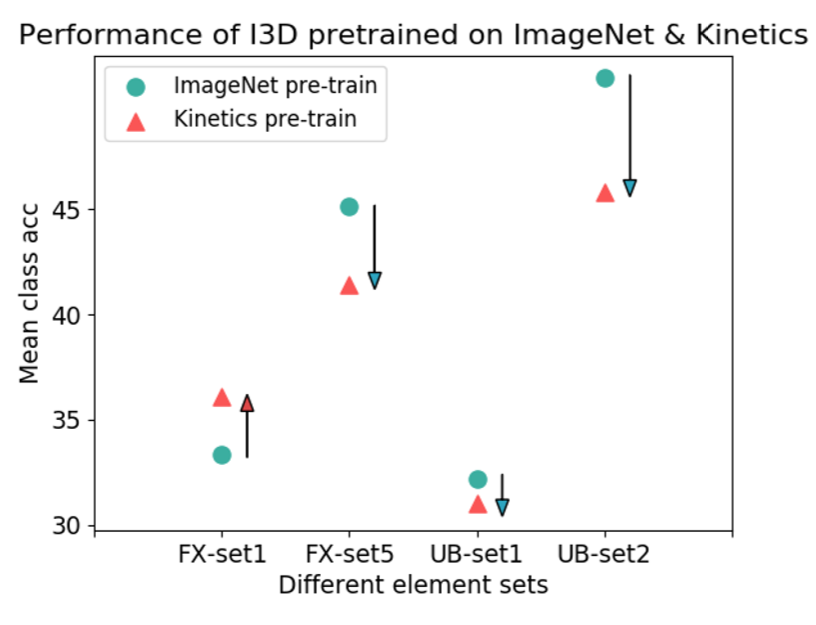
| Per-class performances of I3D pre-trained on Kinetics and ImageNet in various element categories. |

|
| The results of person detection and pose estimation using AlphaPose for a Vault routine. It can be seen that detections and pose estimations of the gymnast are missed in multiple frames, especially in frames with intense motion. These frames are important for fine-grained recognition. (Hover on the GIF for a 0.25x slowdown) |
|
question annotation (json) set-level category list (txt) Gym99 category list (txt) Gym288 category list (txt) Gym530 category list (txt) |
temporal annotation (json) Gym99 train split Gym99 val split Gym288 train split Gym288 val split |
temporal annotation (json) Gym99 train split Gym99 val split (same as v1.0) Gym288 train split Gym288 val split (same as v1.0) |
 |
Shao, Zhao, Dai, Lin. FineGym: A Hierarchical Video Dataset for Fine-grained Action Understanding In CVPR, 2020 (oral). (arXiv) |
 |
(Additional details/ supplementary materials) |
Acknowledgements |
Contact |